Странный это тип OLECHAR, на самом деле это WCHAR:
#if defined(_WIN32) && !defined(OLE2ANSI) typedef WCHAR OLECHAR;
А WCHAR занимает два байта:
typedef unsigned short WCHAR;
Глобально у нас есть два типа кодировки. ANSI - ASCII и UNICODE. Несмотря на то, что ANSI и ASCII разные кодировки суть у них одна. Для кодирования используется один байт. А вот в UNICODE используются два байта.
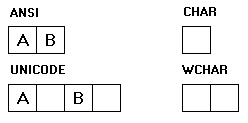
Это все нормально и идея хорошея. Конечно надо поддерживать все символы в одном шрифте. Только плохо, что часть систем Windows работает так, а часть по другому. Вообще меня честно это раздражает. Нет, чтобы перейти сразу на один и все. И кстати надо придумать OLECHAR, а я должен знать, что это WCHAR и так далее. Слов нет прям. Надо нас программистов измучить как только можно. Ну да ладно. OLE работает с широкими символами WCHAR. Нам надо научиться переводить эти символы из одной кодировки в другую. Давайте объявим строку:
#include "stdafx.h"
#include "windows.h"
#include "ole2.h"
#include "iostream.h"
void main()
{
OLECHAR olechar[20];
wcscpy(olechar,L"1.xls");
}
Как вы думаете зачем перед строкой L ?? И думать нечего, наш текст это CHAR, а скомпилироваться должен как WCHAR вот мы и объясняем компилятору, что это WCHAR будь он не ладен. Дальше строку надо заполнить. Это делается функцией wcscpy(), которая аналог strcpy().
strcpy --> wcscpy
Такое преобразование произошло практически со всеми строковыми функциями. То есть не преобразование, а просто функции добавились. Все они описаны в WCHAR.H. Развивая дальше мысль скажу, что есть функция wprintf(), которая умеет выводить нам на экран все-таки эти WCHAR символы.
Для копирования из CHAR в WCHAR применяется функция mbstowcs:
size_t mbstowcs( wchar_t *wcstr, const char *mbstr, size_t count );
Смотрим:
#include "stdafx.h"
#include "windows.h"
#include "ole2.h"
#include "iostream.h"
void main()
{
OLECHAR olechar[20];
char chars[20];
strcpy(chars,"Hello");
mbstowcs((OLECHAR*)&olechar,(CHAR*)&chars,sizeof(chars));
wprintf(olechar);
}
Для обратного процесса WCHAR -> CHAR -> wcstombs:
size_t wcstombs( char *mbstr, const wchar_t *wcstr, size_t count );
Смотрим:
#include "stdafx.h"
#include "windows.h"
#include "ole2.h"
#include "iostream.h"
void main()
{
OLECHAR olechar[20];
wcscpy(olechar,L"Hello OLE");
char chars[20];
wcstombs((CHAR*)&chars,(OLECHAR*)&olechar,sizeof(chars));
cout << chars << endl;
}