В прошлом шаге был обсужден вопрос создания собственной таблицы. Но у выбранной мною структуры есть недостатки. Как быть, например, если у человека несколько телефонов, десяток адресов почты и т.п. Можно, конечно, записать все в одну таблицу, но тогда большая часть информации (даже у нас – name_ (имя)) будет дублироваться. Для этого и придуманы реляционные базы данных (реляционный значит связанный).
Я умышленно добавил в таблицу прошлого шага поле mancode (код человека), хотя вовсе не собирался его использовать. Вообще, в вещах такого плана всегда неплохо иметь уникальное поле (значение которого не повторяется). Ведь кто знает, какая выборка понадобится в будущем :-)
Ну, а как же сделать красиво? Можно создать свою базу данных. В окне Project Manager идем в Data\Databases и жмем New. Дадим своей БД имя birthday.dbc.
Добавим в нашу БД три таблицы. В people.dbf будем хранить имя, дату рождения, дополнительную информацию и, самое главное, код, который поможет связываться с другими таблицами. Заведем еще две таблицы: одна (phones.dbf) - с телефонами, другая (emales.dbf) - с адресами электронной почты:
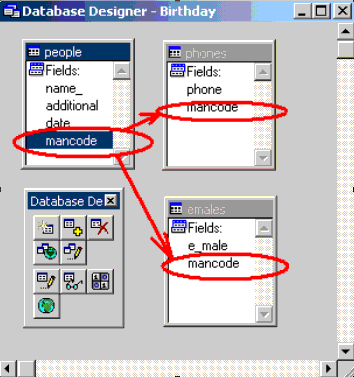
В двух последних таблицах также заведем поле с кодом, значение которого совпадает со значением этого поля в people. Ну вот, при условии, что все заполнено, можно провязать так:
select * from birthday!people, birthday!phones, birthday!emales where; people.mancode=phones.mancode and people.mancode=emales.mancode
Это, конечно, не лучший, зато весьма наглядный вариант.
Как видите, придерживаться одинаковых названий полей, по которым идет провязка таблиц, вовсе необязательно, главное чтобы значения в них совпадали.
Для того, чтобы сделать все окончательно честно, добавим в таблицу people primary-индекс по полю mancode. Идея здесь проста, нельзя иметь одинаковый код для разных людей, иначе провязки будут неправильные. Индексация поможет и быстродействие повысить. Подробнее на этом я остановлюсь в следующих шагах, а пока изменяем таблицу:
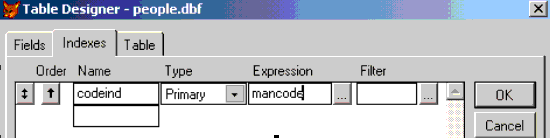
Таким образом, следить за уникальностью мы поручили непосредственно VFP. При невыполнении заданного условия получаем ошибку:
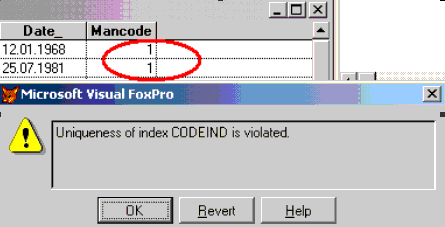
В результате мы получили довольно стройную структуру. При больших объемах такая БД будет занимать гораздо меньше места на диске чем одна таблица. Плюс, данные легко изменять, не касаясь связанных полей.